




NeurIPS 2025: Sony AI’s Latest Contributions
Events
December 1, 2025
NeurIPS 2025 brings together work across Sony AI that targets real problems in real settings. The research in this roundup focuses on models that adapt under constraints, handle fragmented or sensitive data, support creators, and make decisions that hold up when conditions change. Each project moves toward systems that behave more consistently and more transparently. The goal is the same across every group: make AI easier to trust, easier to evaluate, and easier to use in complex environments. We encourage you to dive into our research highlights below to learn more about our contributions.
Imaging & Sensing (PPML)
Sony AI’s Imaging and Sensing work at NeurIPS 2025 focuses on problems that appear when models move into real-world environments. The papers in this group look at fine-tuning under constraints, federated adaptation across domains, instruction reliability, medical perception, and ways to trace unauthorized dataset use. Each contribution addresses a concrete technical gap and offers a path toward more dependable performance in practice.
StelLA: Subspace Learning in Low-Rank Adaptation using Stiefel Manifold
Authors: Zhizhong Li, Sina Sajadmanesh, Jingtao Li, Lingjuan Lyu
Code is available at https://github.com/SonyResearch/stella.
Large foundation models have changed the pace of machine learning. They power everything from language tasks to vision systems to multi-modal work. But their size comes at a cost. As the researchers explain, “...their substantial scale creates significant computational and storage demands, which can limit broader adoption for task-specific fine-tuning.”
StelLA proposes a structured way to fine-tune large models using low-rank adaptation. Instead of letting LoRA matrices drift, the method keeps their subspaces orthonormal by optimizing them on the Stiefel manifold. The adapter then has a clear form: two orthonormal matrices that define direction, and one matrix that controls scale.
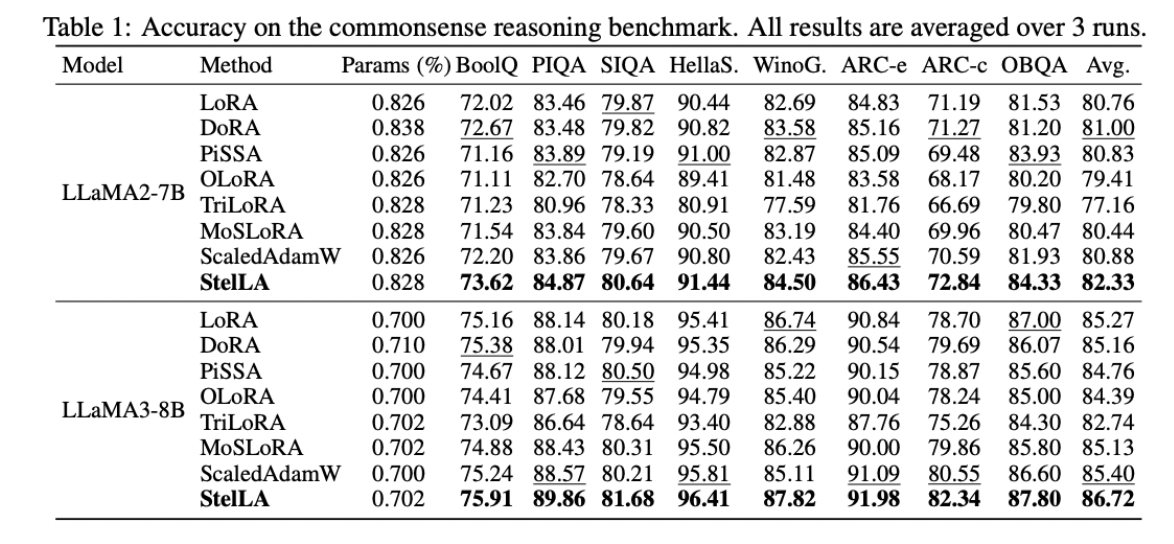
The team evaluated StelLA across language and vision tasks. It produced stronger results than standard LoRA in areas such as commonsense reasoning, instruction following, math, code generation, and image classification, without major increases in parameters or compute.
StelLA offers a more controlled approach to fine-tuning foundation models when full training isn’t possible.
EnTruth: Enhancing the Traceability of Unauthorized Dataset Usage in Text-to-Image Diffusion Models with Minimal and Robust Alterations
Authors: Jie Ren, Yingqian Cui, Chen Chen, Vikash Sehwag, Yue Xing, Jiliang Tang, Lingjuan Lyu
Workshop: GenProCC, https://genprocc.github.io/
Text-to-image generative models have improved dramatically in recent years. They can create detailed, realistic images because they use stronger architectures, more computing power, and extremely large datasets. But those datasets—often containing copyrighted or sensitive images—face a major challenge: there’s still no reliable way to protect them from being used without permission.
Think of today’s protection methods like weak security systems.
Some approaches try to “poison” the data (i.e., add hidden signals), but they require so much distortion that the images become visibly worse. Others, like membership-inference checks, act more like flimsy locks—they can sometimes detect misuse, but they’re not accurate or dependable.
EnTruth introduces a different idea. Instead of trying to hide or degrade the data, it plants a small, carefully designed “template” inside the images. Something like a subtle pattern. If another model trains on these images without permission, that model unintentionally learns this pattern. Later, when prompted, the model reveals that hidden learning in a very specific way.

The mechanism is simple: a small set of images is built around a shared template with varied foreground objects. Models fine-tuned on this data reproduce the hidden template when prompted, making detection straightforward. The signal survives common preprocessing steps, including JPEG compression, resizing, Gaussian blur, grayscale conversion, and deep noise purification. It also survives re-captioning because the varied foregrounds act as soft triggers.
EnTruth works at very low alteration rates and preserves image quality close to clean baselines. It’s compatible with full fine-tuning, LoRA, and API-based training.
SHIELD: A Benchmark Study on Zero-Shot Detection of AI-Edited Images with Vision-Language Models
Authors: Siyuan Cheng, Hanxi Guo, Zhenting Wang, Xiangyu Zhang, Lingjuan Lyu
Workshop: GenProCC, https://genprocc.github.io/
Code: https://github.com/Megum1/SHIELD
Generative AI now makes it easy to edit small regions of real images with convincing detail. Those localized edits are increasingly used to spread misinformation, but most existing detectors were built for full-image synthesis or DeepFakes, and they often miss these partial manipulations. As the authors warn, “For example, it is disturbingly straightforward to generate realistic images that fabricate sensational stories, such as falsely depicting public figures in controversial situations. Such misuse undermines the trustworthiness of generative AI and poses significant challenges for its safe deployment. Hence, developing reliable methods to detect synthetic images is of urgent importance.”
Enter SHIELD. It evaluates how well vision-language models can flag AI-edited images in a zero-shot setting. The benchmark includes localized edits such as object replacements, background changes, attribute shifts, and image-to-image transformations.
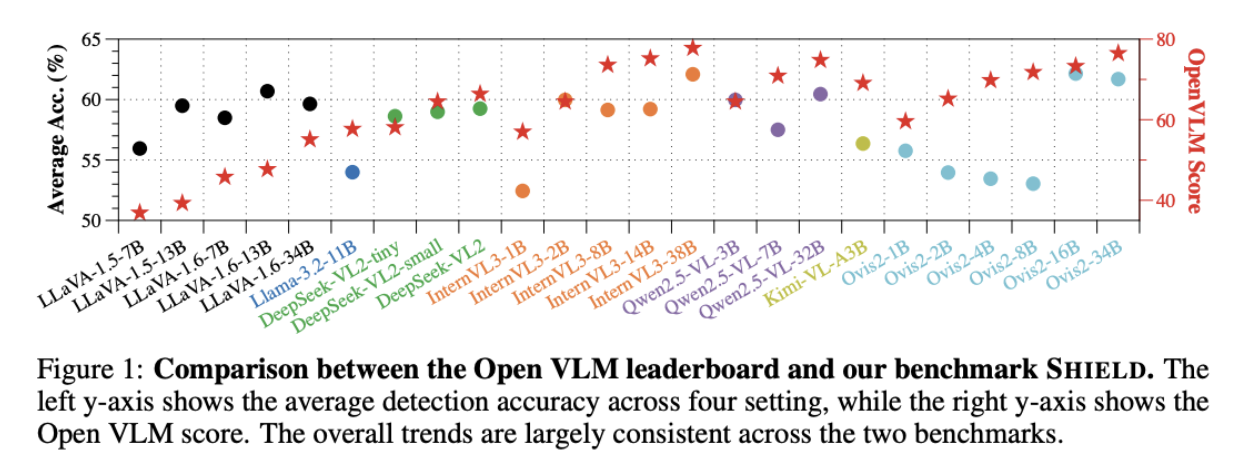
The team tested 24 models across prompting and inference modes. Performance largely mirrored general VLM capability. Simple prompting with greedy decoding often worked better than reasoning-based strategies. Accuracy dropped when edits were fine-grained or subtle.
SHIELD offers a consistent way to measure how current VLMs handle real-world edit detection without task-specific training.
PolypSense3D: A Multi-Source Benchmark Dataset for Depth-Aware Polyp Size Measurement in Endoscopy
Authors: Ruyu Liu, Lin Wang, Mingming Zhou, Jianhua Zhang, Haoyu Zhang, Xiufeng Liu, Xu Cheng, Sixian Chan, Yanbing Shen, Sheng Dai, Yuping Yang, Yaochu Jin, Lingjuan Lyu
Dataset: https://doi.org/10.7910/DVN/LKDIEK
Code: https://github.com/HNUicda/PolypSense3D
As the authors aptly explain, “Accurate polyp sizing during endoscopy is crucial for cancer risk assessment but is hindered by subjective methods and inadequate datasets lacking integrated 2D appearance, 3D structure, and real-world size information.” To help with this challenge, the team introduces PolypSense3D, a benchmark for depth-aware polyp size measurement. It includes more than 43,000 frames from simulations, 3D-printed phantoms, and clinical endoscopy. Each image contains RGB, depth, calibrated camera parameters, and millimeter-level size annotations obtained using a forceps-based protocol.
The team evaluated segmentation and depth models across all three sources. Performance varied noticeably. Models that handled simulations or phantom data well often struggled with clinical sequences. When segmentation or depth estimates drifted, size predictions reflected those errors. On clinical cases, the strongest pipeline reached about 0.95 mm MAE.
The benchmark gives researchers a unified place to test size-measurement pipelines under realistic conditions and to study how perception differences influence quantitative predictions.
LIFEBench: Evaluating Length Instruction Following in Large Language Models
Authors: Wei Zhang, Zhenhong Zhou, Kun Wang, Junfeng Fang, Rongwu Xu, Yuanhe Zhang, Rui Wang, Ge Zhang, Xinfeng Li, Li Sun, Lingjuan Lyu, Yang Liu, Sen Su
Data & Code: github.com/LIFEBench/LIFEBench
Data & Dataset Card: huggingface.co/datasets/LIFEBench/LIFEBench
Homepage: ydyjya.github.io/LIFEBench
LIFEBench tests how reliably modern LLMs follow explicit length instructions—a task many models still mishandle despite strong reasoning abilities. The benchmark contains 10,800 examples in English and Chinese across four task types, with requested lengths ranging from 16 to 8,192 words. It evaluates 26 widely used models.
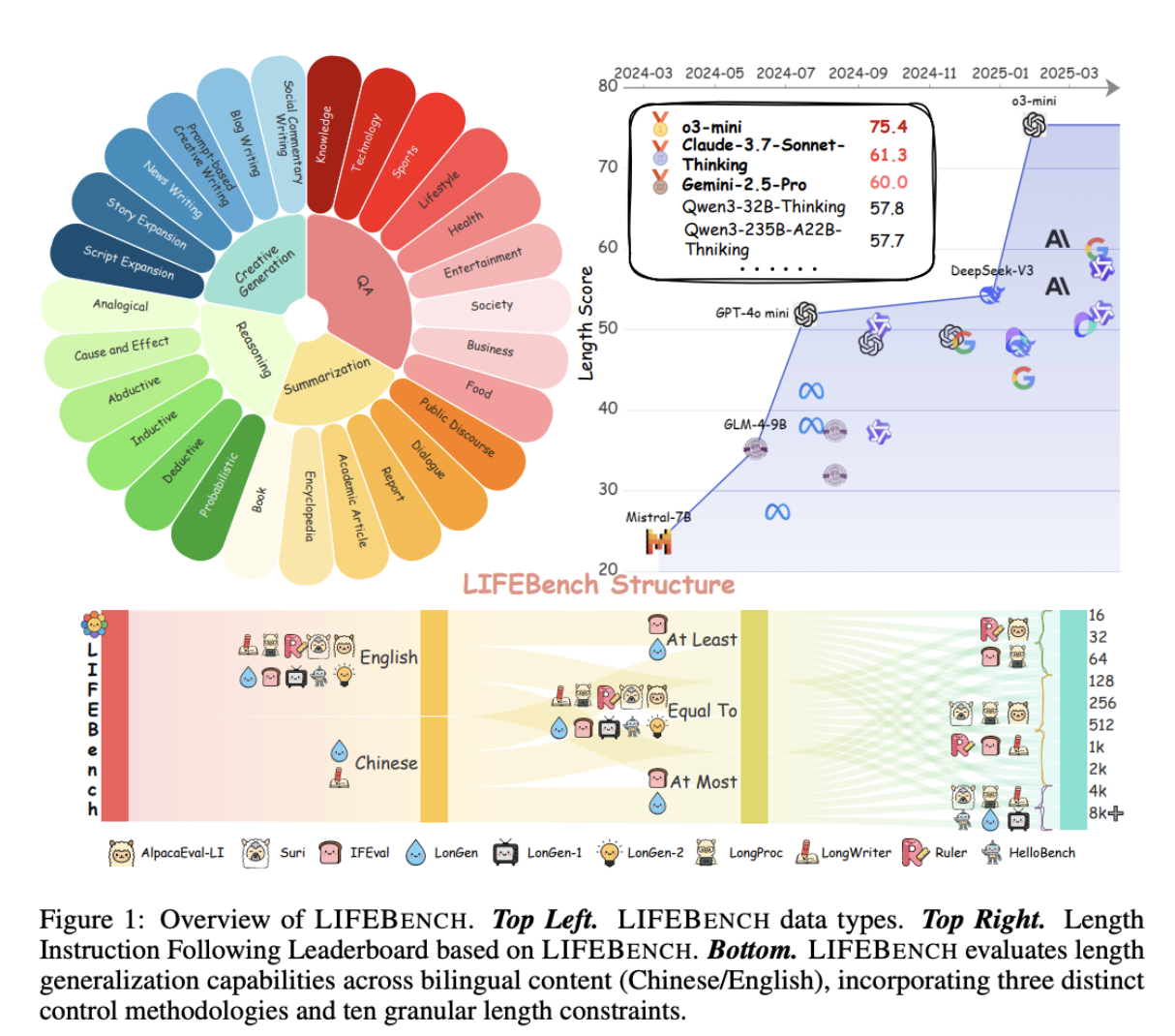
Most models manage short targets but break down as lengths increase. Outputs often terminate early, drift off target, or fall far below the vendor-claimed maximum generation limits, even when tested up to 32K words. Longer context windows don’t solve the issue, while reasoning-focused models perform better than systems built specifically for long-form generation.
LIFEBench provides a direct, structured way to compare length-control behavior and highlights a fundamental limitation in current LLMs.
FlowerTune: A Cross-Domain Benchmark for Federated Fine-Tuning of Large Language Models
Authors: Yan Gao, Massimo R. Scamarcia, Javier Fernandez-Marques, Mohammad Naseri, Chong Ng, Dimitris Stripelis, Zexi Li, Tao Shen, Jiamu Bai, Daoyuan Chen, Zikai Zhang, Rui Hu, InSeo Song, KangYoon Lee, Hong Jia, Ting Dang, Junyan Wang, Zheyuan Liu, Daniel J. Beutel, Lingjuan Lyu, Nicholas Lane
While it is widely acknowledged that increased data volume typically enhances model performance, recent studies have raised concerns that the supply of high-quality public data may be exhausted within a few years, the authors explain.
Moreover, there is an increasing demand for specialized LLMs that can integrate domain-specific knowledge not readily accessible in publicly available web-based corpora, particularly in sensitive domains such as healthcare and finance.
FlowerTune is the first broad benchmark for federated fine-tuning of LLMs across general NLP, finance, medical, and coding tasks. It evaluates 26 pre-trained models when data remains local and only updates are shared. This is a setup that matters as high-quality public data becomes scarce and sensitive domains can’t centralize their datasets, which is an increasing industry concern.
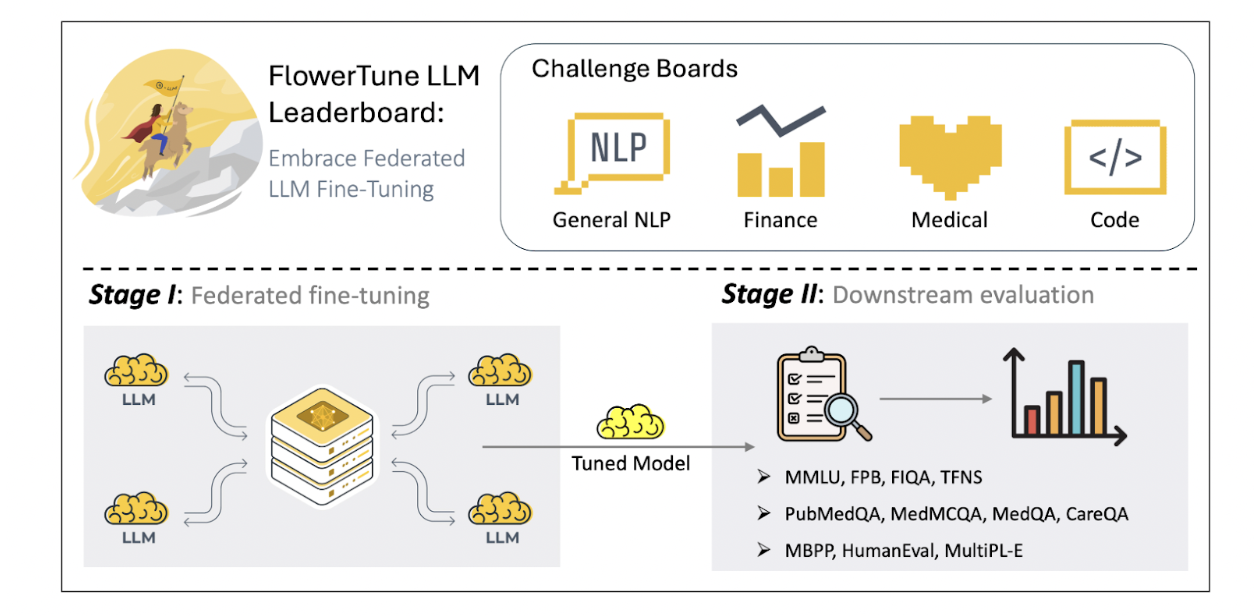
The suite captures how models adapt under real federated constraints, including domain shift, communication strategies, aggregation choices, and resource limits. Because it’s built through an open-source, community-driven effort, FlowerTune offers a clear, comparable view of how LLMs behave when privacy and specialization both matter.
AI for Creators
AI for Creators this year focuses on problems that show up when artists try to use generative models in real work. The papers in this group move toward clearer evaluation, cleaner datasets, and more control over how models produce sound and video. The through line is consistency: give creators tools they can trust, and remove the guesswork that slows real creative workflows.
Each contribution solves a specific gap. Some address how we measure quality. Others look at how to generate long-form material without losing coherence. A few center on production needs, like speed, stability, and better motion data. Together, they point toward systems that support artists’ intent and keep the process predictable.
Creative & Protective AI for Music and Entertainment
Expo Workshop
Sony AI’s “Creative and Protective AI for Music and Entertainment” has been selected as one of this year’s NeurIPS Expo workshops—an opportunity reserved for sponsors and submitted through Sony AI. The workshop brings together artistic creation and responsible model behavior, spotlighting work across multimodal datasets, controllable speech and sound generation, and mechanisms that safeguard creators’ rights. It reflects the same dual focus that runs through our AI for Creators work: expanding what artists can make, while building the protective tooling that ensures their contributions remain respected.
For more information, visit the workshop page here: https://neurips.cc/virtual/2025/128679
Music Arena: Live Evaluation for Text-to-Music
Authors: Yonghyun Kim, Wayne Chi, Anastasios Angelopoulos, Wei-Lin Chiang, Koichi Saito, Shinji Watanabe, Yuki Mitsufuji, Chris Donahue
Project Page: music-arena.org
Preference Data: huggingface.co/music-arena
Music Arena introduces the first open, continuously updating platform for evaluating text-to-music (TTM) systems using real human preferences at scale. As the authors explain, in TTM research, the best way to judge a system is still simple: have people listen to the generated music and say what they prefer. But doing these listening studies is slow, expensive, and hard to compare because everyone runs their studies differently. Unlike these one-off listening studies, Music Arena standardizes how TTM models are tested, and releases anonymized preference data on a rolling basis.
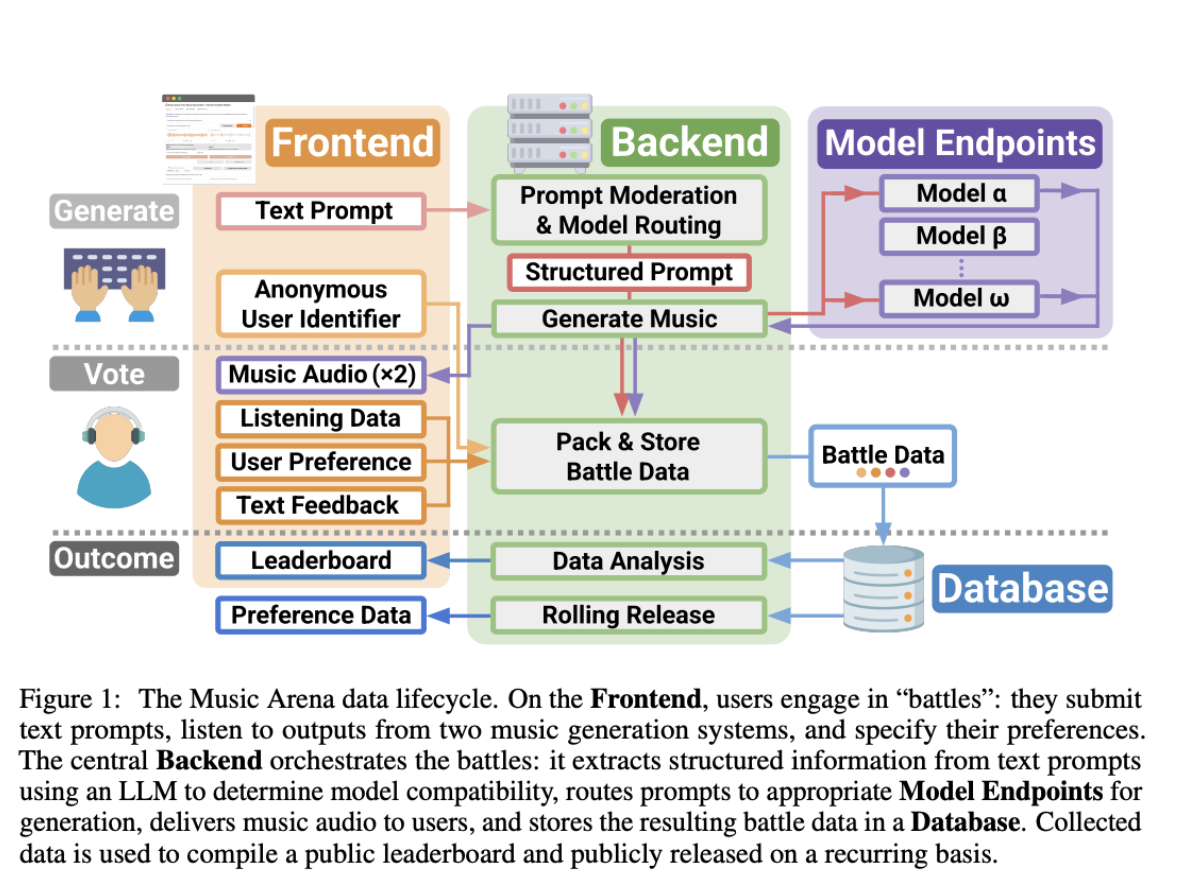
The platform runs “battles.” Meaning, users submit a free-form text prompt, listen to two generated clips, and choose the preferred result (or select tie/both bad). The backend handles prompt moderation, model compatibility, and generation orchestration. An LLM routes prompts to models that support vocals, lyrics, or duration constraints. Because music must be consumed in real time, the system captures fine-grained listening behavior and unlocks “voting” only after users listen for a minimum duration.
Music Arena also surfaces metadata that matters for creative use, including training-data provenance and real-time-factor (RTF) generation speed. Both are integrated into publicly released leaderboards. All code (minus private keys) is open source, and preference data is released monthly with salted-hash user identifiers for privacy.
The work provides a rigorous, renewable evaluation protocol for text-to-music research and a transparent dataset reflecting real-world usage patterns.
TalkCuts: A Large-Scale Dataset for Multi-Shot Human Speech Video Generation
Authors: Jiaben Chen, Zixin Wang, Ailing Zeng, Yang Fu, Xueyang Yu, Siyuan Cen, Julian Tanke, Yihang Chen, Koichi Saito, Yuki Mitsufuji, Chuang Gan
Project Page: talkcuts.github.io
TalkCuts is a new, very large dataset built to help researchers create AI models that can generate realistic videos of people speaking: not just from a single static camera angle, but across multiple camera shots. Most existing datasets only show a person from one viewpoint, which limits what models can learn.

TalkCuts is different: it contains 164,000 clips (over 500 hours total) with close-up, half-body, and full-body shots from more than 10,000 different people. Each clip includes synchronized transcripts, audio, 2D whole-body keypoints, and 3D SMPL-X motion data, covering more than 10,000 identities. Shot types span close-up, half-body, full-body, and wide views.
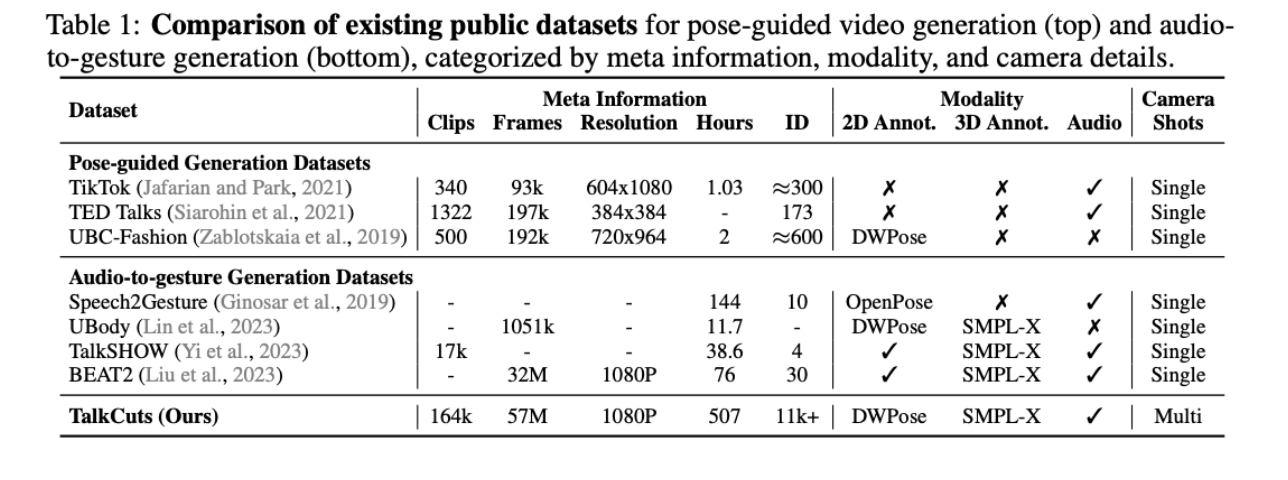
Existing datasets typically focus on single-shot, short-form content and offer limited multimodal annotation. Table 1 (shown above) shows that TalkCuts is the only public dataset providing both multi-shot labeling and full 2D + 3D motion annotations at this scale. The dataset is curated using scene detection, person filtering, pose confidence checks, and a multi-stage SMPL-X refinement pipeline to ensure high-quality motion and gesture data.
The authors also introduce Orator, a baseline model demonstrating how TalkCuts can be used for long-form, multi-shot video synthesis. Orator combines a DirectorLLM, (which plans camera transitions, gestures, and vocal delivery), with a multimodal generation module that produces synchronized speech audio and video clips. Training on TalkCuts improves shot coherence, identity preservation, and motion quality across audio-driven and pose-guided settings. It also outperforms existing systems such as SadTalker, EchoMimicV2, and Hallo3.
TalkCuts provides the first comprehensive benchmark for generating coherent multi-shot human speech videos and establishes a foundation for future work on controllable, long-form multimodal video generation.
“Studies for”: A Human–AI Co-Creative Sound Artwork Using a Real-time Multi-channel Sound Generation Model
[Creative AI Track, Poster]
Authors: Chihiro Nagashima, Akira Takahashi, Zhi Zhong, Shusuke Takahashi, Yuki Mitsufuji
Demo Page: sony.github.io/studies-for/
Exhibition: ICC Tokyo, Dec 2024–Mar 2025
“Studies for” is an eight-channel generative sound installation created with sound artist Evala. It uses SpecMaskGIT—a lightweight, high-quality sound generation model—to synthesize and play audio in real time for the full three-month exhibition. The system was trained exclusively on more than 200 hours of Evala’s past sound artworks, resampled at 48 kHz to preserve the spatial and textural detail central to his style.

The work explores a “new form of archive”—using an AI model to preserve an artist’s sonic identity while generating new material that extends beyond what the artist previously created. To achieve this, the team emphasized three requirements for AI-driven art-making: incorporating direct artist feedback, training on the artist’s own body of work, and enabling the model to produce novel, unexpected sound outputs.
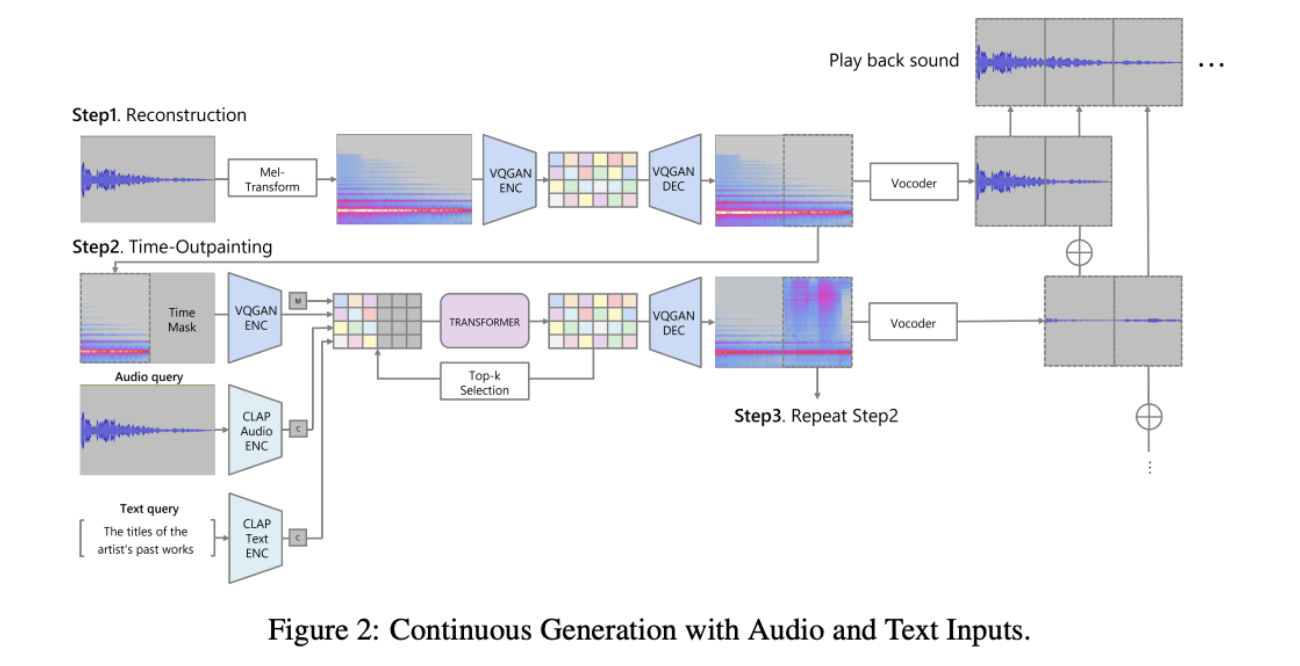
SpecMaskGIT was optimized for fast, uninterrupted generation across eight channels. Compared to the settings when SpecMaskGIT was proposed, the model here was reduced from 24 to 12 Transformer blocks, lowering the parameter count to 89M, and the vocoder was replaced with Vocos to meet real-time speed requirements. Audio was generated in 10-second overlapping windows to maintain continuity. The installation ran on dual RTX 4080 GPUs and a multichannel audio interface system powering an eight-speaker spatial array.
To avoid outputs that merely resembled recombined fragments of older works, the conditioning mechanism was expanded beyond audio prompts. Alongside Evala’s signature opening sound, the model also used CLAP text embeddings of eight prior artwork titles. Each of the eight channels was guided by its associated title, encouraging abstract reinterpretations rather than literal reuse. This audio-text dual conditioning, implemented through a modified classifier-free guidance formulation, enabled the model to generate material that remained stylistically faithful while introducing new sonic motifs.
“Studies for” demonstrates how a lightweight, fast-generating model can support iterative artist feedback and real-time multi-channel synthesis. As the authors explain, “This approach aims to preserve the artist’s style while continuing to generate the sounds of their work even after the artist’s death, proposing a new form of archive.” This work presents new possibilities for artistic creation beyond the artist’s lifetime.
Blind Inverse Problem Solving Made Easy by Text-to-Image Latent Diffusion
[Workshop Paper]
Authors: Michail Dontas, Yutong He, Naoki Murata, Yuki Mitsufuji, J. Zico Kolter, Ruslan Salakhutdinov
Workshop: Structured Probabilistic Inference and Generative Modeling
Workshop: https://spigmworkshopv3.github.io/
LADiBI is a training-free method for blind inverse problems. It uses text-to-image latent diffusion models to represent both the unknown image and the unknown operator. Clean-image traits are provided with positive prompts, and degradation cues are captured by negative prompts.

The method starts by estimating a rough operator using quick, low-step diffusion samples. It then refines both the operator and the reconstruction throughout the diffusion process. This supports linear kernels and neural-network–based operators alike.
LADiBI performs strongly across Gaussian blur, motion blur, and JPEG decompression, and it is the only tested method that handles blind JPEG decompression without knowing the compression details. It also restores artwork: the paper shows LADiBI “effectively generates images consistent with both the measurement image and the painting style” in blind deblurring of Monet paintings (see Fig 4 below).

FlashFoley: Fast Interactive Sketch2Audio Generation
Authors: Zachary Novack, Koichi Saito, Zhi Zhong, Takashi Shibuya, Shuyang Cui, Julian McAuley, Taylor Berg-Kirkpatrick, Christian Simon, Shusuke Takahashi, Yuki Mitsufuji
Paper: NeurIPS 2025 Workshop on AI for Music
Audio Samples: anonaudiogen.github.io/web
FlashFoley is the first open-source sketch-to-audio system that is both controllable and fast enough for interactive use. It extends the Sketch2Sound framework by adding pitch, volume, and brightness controls through lightweight linear adaptation, allowing users to drive generation with time-varying “sketches” or vocal imitations.
The model is accelerated with Adversarial Relativistic Contrastive (ARC) post-training and generates 11.88 seconds of stereo 44.1 kHz audio in 75 ms — roughly 10× faster than earlier controllable text-to-audio systems. Control accuracy also improves despite the reduced number of inference steps.
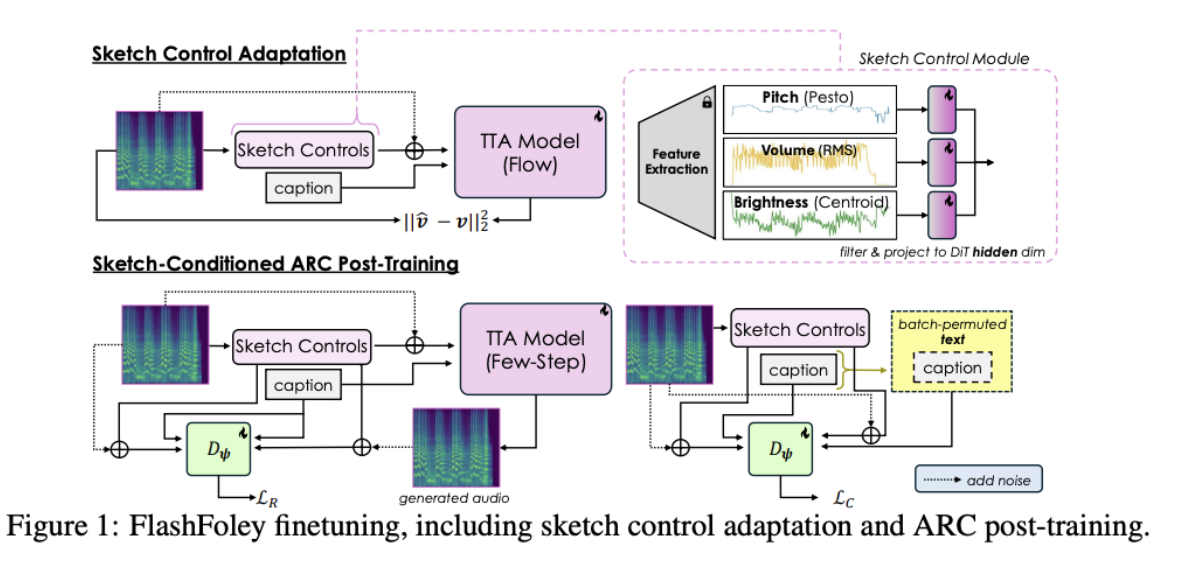
To enable real-time interaction, the authors introduce a zero-shot block-autoregressive streaming algorithm. This lets the model stream audio as sketch controls arrive, using overlapping latent chunks and equal-power crossfades to avoid boundary artifacts. This reduces streaming latency to about six seconds while maintaining stable audio quality.
On the VimSketch dataset, FlashFoley outperforms the base model in control following and achieves strong text-audio alignment, while retaining low generation latency.FlashFoley provides a practical, open-source foundation for real-time sketch-conditioned audio generation and creative sound design workflows.
Chief Scientist, Peter Stone’s, Contributions at NeurIPS on Agents That Understand and Adapt
Sony AI’s Chief Scientist, Peter Stone’s contributions at NeurIPS focus on how agents learn. His work also looks at how they respond when conditions shift. A tertiary thread examines how agents turn language into action without task-specific training. Each paper tackles a separate limitation that shows up in real deployments. Dr. Stone also joins talks and workshops that highlight how these ideas move into applied settings. Together, the work points toward agents that are more grounded and more dependable, with clearer paths toward practical use.
Dyn-O: Building Structured World Models with Object-Centric Representations
Authors: Zizhao Wang, Kaixin Wang, Li Zhao, Peter Stone, Jiang Bian
Dyn-O looks at a basic question in world-modeling: if most environments are made of interacting objects, why do so many models still treat scenes as a single block of features? The authors build a model that avoids that oversimplifying assumption. Dyn-O learns scene structure by separating an observation into a set of object-specific “slots,” then predicts future states by updating each slot over time.
The model improves two areas that have held object-centric world models back. First, it learns cleaner object representations by borrowing priors from large segmentation models during training, then phasing that guidance out so inference stays efficient. Second, it uses a state-space model to handle dynamics, which helps keep interactions stable across long rollouts.
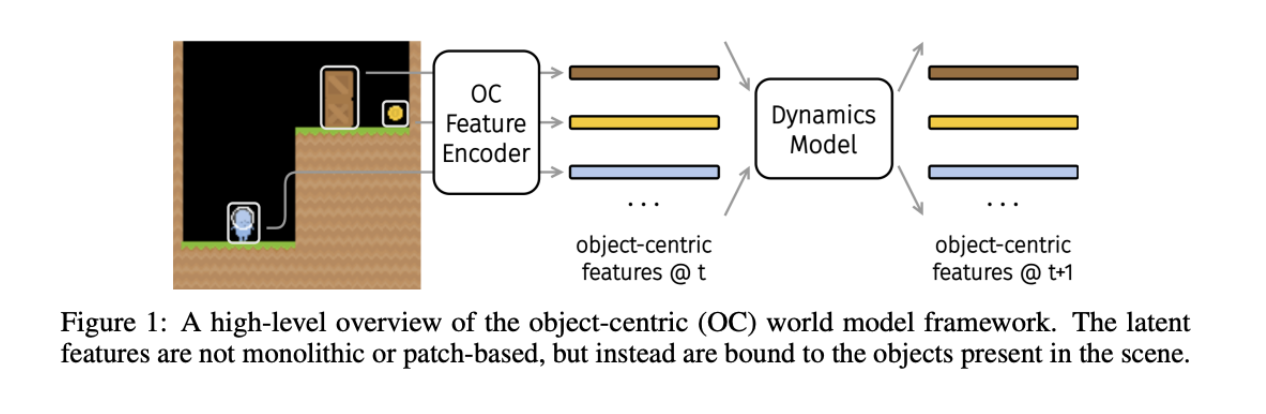
Once the model has these object-level slots, it splits each slot into static and dynamic parts. Static features track appearance. Dynamic features track motion. This separation lets the model change one without altering the other. In the paper, this allows simple edits—like changing an avatar’s color—while keeping the motion identical.
The results are strongest in Procgen. Dyn-O predicts future frames with clearer object boundaries and better temporal consistency than DreamerV3. It also outperforms baselines in how well it binds objects to slots and how well it generalizes to unseen levels. The static-dynamic split is also validated: static features carry color and texture, dynamic features carry movement and size, and the two don’t leak into each other. Overall, Dyn-O shows that object-centric world models can scale beyond toy domains.
RLZero: Direct Policy Inference from Language Without In-Domain Supervision
Authors: Harshit Sikchi, Siddhant Agarwal, Pranaya Jajoo, Samyak Parajuli, Caleb Chuck, Max Rudolph, Peter Stone, Amy Zhang, Scott Niekum
RLZero looks at how to turn language instructions into behavior without labeled demos or reward design. The goal is simply stated: produce a usable policy from text alone.
The method follows three steps. A video model imagines what the instruction should look like. Those imagined frames are then matched to real observations from an offline dataset. A behavior foundation model uses that grounded sequence to infer a policy in closed form, with no fine-tuning or test-time training.
Across locomotion and humanoid tasks, the approach generates behaviors that reflect the instruction and holds up even when the demonstration comes from a different embodiment. The results show that pairing imagined trajectories with unsupervised RL can provide direct language-to-policy transfer without supervision.
Evaluating Generalization Capabilities of LLM-Based Agents in Mixed-Motive Scenarios Using Concordia
Authors: Chandler Smith, Marwa Abdulhai, Manfred Diaz, Marko Tesic, Rakshit Trivedi, Sasha Vezhnevets, Lewis Hammond, Jesse Clifton, Minsuk Chang, Edgar A. Duéñez-Guzmán, John P Agapiou, Jayd Matyas, Danny Karmon, Beining Zhang, Jim Dilkes, Akash Kundu, Jord Nguyen, Emanuel Tewolde, Jebish Purbey, Ram Mohan Rao Kadiyala, Siddhant Gupta, Aliaksei Korshuk, Buyantuev Alexander, Ilya Makarov, Gang Zhao, Rolando Fernandez, Zhihan Wang, Caroline Wang, Jiaxun Cui, Lingyun Xiao, Di Yang Shi, Yoonchang Sung, Arrasy Rahman, Peter Stone, Yipeng Kang, Hyeonggeun Yun, Ananya Ananya, Taehun Cha, Zhiqiang Wu, Elizaveta Tennant, Olivia Macmillan-Scott, Marta Emili García Segura, Diana Riazi, Fuyang Cui, Sriram Ganapathi Subramanian, Toryn Q. Klassen, Nico Schiavone, Mogtaba Alim, Sheila A. McIlraith, Manuel Sebastian Rios Beltran, Oswaldo Peña, Carlos Saith Rodriguez Rojas, Manuela Chacon-Chamorro, Ruben Manrique, Luis Felipe Giraldo, Nicanor Quijano, Yiding Wang, Yuxuan Chen, Fangwei Zhong, Mengmeng Wang, Wenming Tu, Zhaowei Zhang, Ziang Chen, Zixia Jia, Xue Feng, Zilong Zheng, Chichen Lin, Weijian Fan, Chenao Liu, Sneheel Sarangi, Ziyan Wang, Shuqing Shi, Yali Du, Avinaash Anand Kulandaivel, Yang Liu, Wu Ruiyang, Chetan Talele, 陆孙嘉, Gema Parreño Piqueras, Shamika Dhuri, Bain McHale, Tim Baarslag, Dylan Hadfield-Menell, Natasha Jaques, Jose Hernandez-Orallo, Joel Z Leibo
NeurIPS Poster Site: https://neurips.cc/virtual/2025/poster/121382
This research (resulting from a NeurIPS 2024 competition co-authored by the organizers and participants) studies how LLM-based agents behave when their incentives aren’t aligned. Most evaluations test cooperation or competition in isolation, but mixed-motive settings create situations where agents may cooperate, defect, or toggle between the two. The authors use Concordia, a multi-agent benchmarking platform, to measure how well current models handle these shifts.
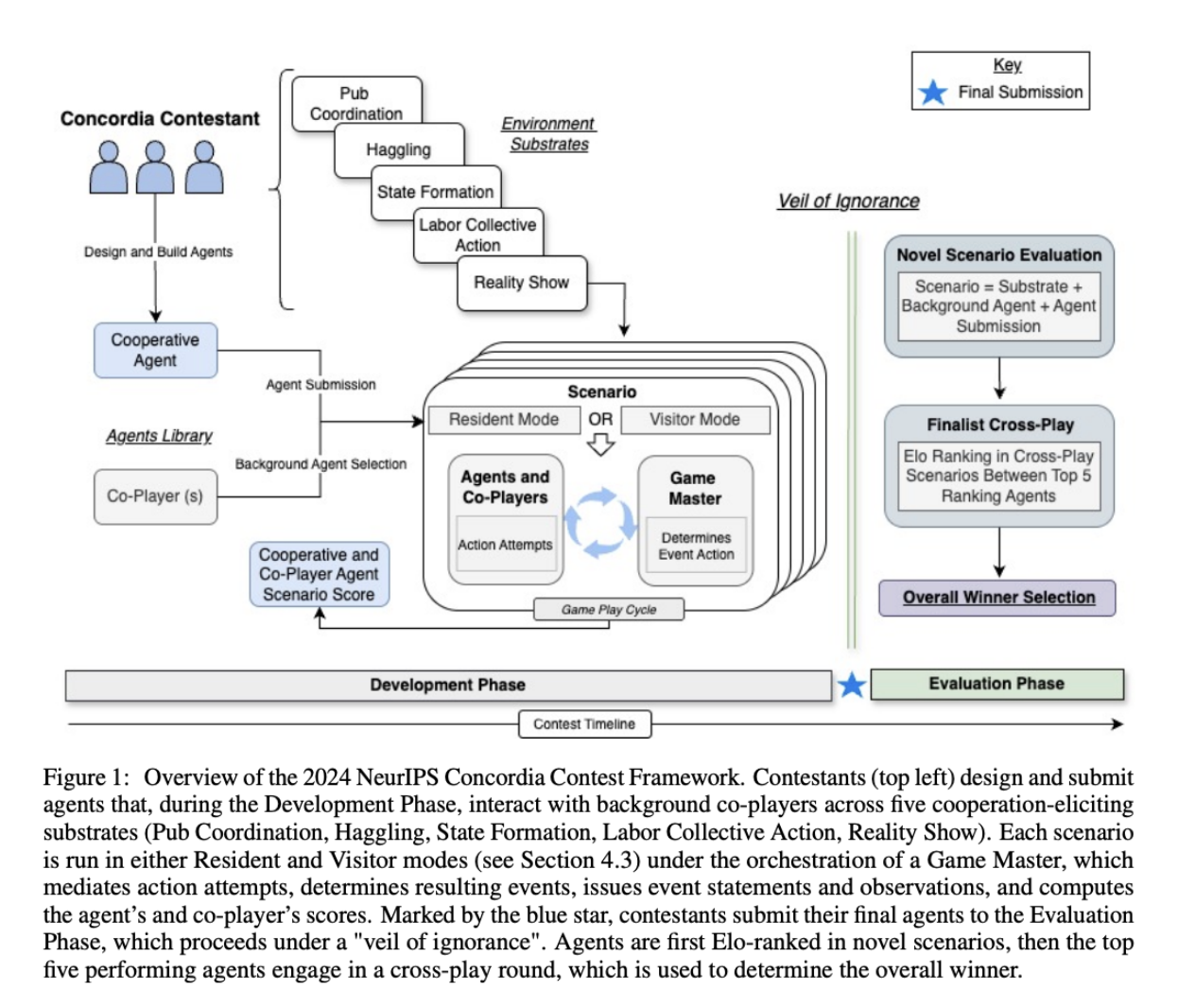
The experiments compare several LLM agents across a set of tasks that require planning, adaptation, and reasoning about others’ decisions. The setup includes turn-based interactions, role descriptions, and hidden or changing incentives. The goal is to test whether these agents can generalize their behavior when the structure of the environment changes.
Across tasks, the models show inconsistent generalization. Some agents cooperate when prompted but fail to maintain that cooperation as incentives shift. Others reason well about short-term moves but lose track of longer-term outcomes. The paper highlights cases where agents appear to understand mixed motives but revert to brittle, pattern-driven decisions when conditions change.
The results suggest that LLM-based agents remain limited in dynamic multi-agent scenarios. They can follow instructions and model simple interactions, but they struggle when incentives conflict or evolve, which is the core requirement of mixed-motive settings.
NEURIPS 2025: KEYNOTES & WORKSHOPS
Peter Stone Talk on Embodied World Models
A NeurIPS Workshop invite talk discussing embodied world models and how agents learn structure through interaction.
Visit for more information: https://embodied-world-models.github.io/
AI SaaS Workshop Keynote – Iso Daisuke
A keynote exploring applied AI and deployment challenges for large-scale systems.
Visit for more information: https://sites.google.com/view/l2s-workshop/home
CLOSING
The work highlighted here shows a steady push toward practical, resilient AI systems. The teams focused on clarity, control, and grounded behavior rather than scale for its own sake. They also looked at how these ideas can support creators, clinicians, and developers who need models that respond reliably. As these methods evolve, the path forward becomes clearer: build systems that learn from the world as it is, adapt when the world shifts, and support the people who depend on them.
For more information on NeurIPS 2025, visit: https://neurips.cc/
Latest Blog

February 2, 2026 | Sony AI
Advancing AI: Highlights from January
January set the tone for the year ahead at Sony AI, with work that spans foundational research, scientific discovery, and global engagement with the research community.This month’s…

January 30, 2026 | Sony AI
Sony AI’s Contributions at AAAI 2026
Sony AI’s Contributions at AAAI 2026AAAI 2026 is a reminder that progress in AI isn’t one straight line. This year’s Sony AI contributions span improving and enhancing continual le…

January 26, 2026 | Sony AI
How Sony AI’s Scientific Discovery Team is Reimagining How Researchers Evaluate …
In today’s research landscape, thousands of scientific papers are published each day; a metaphorical sea of knowledge. Even domain experts struggle to keep up. As Pablo Sánchez Mar…

